Building a Computer Vision Tool for Gymnastics Coaching

This project emerged from a common challenge faced by gymnastics coaches: while simple diagrams are often the most effective way to explain complex movements to students, converting video footage into clear, digestible diagrams has traditionally been a manual and time-consuming process.
It started because my partner asked if ChatGPT could create an image sequence of a coaching video to help break things down. By chance ChatGPT actually offered to give me code to do this, which got me wondering how hard pose estimation would be based on an image sequence.
| Original | Pose Detection | Composite |
|---|---|---|
 |  |  |
The Challenge
In gymnastics coaching, while video replay is a valuable tool, it can sometimes overwhelm students with too much visual information. The challenge was to create a tool that could automatically transform video footage into simple, diagram-like representations that coaches could use for clearer instruction. Specifically, we needed a system that could:
- Automatically track an athlete's body positions throughout their routine
- Convert complex video footage into simple, clear body position diagrams
- Create visual overlays that highlight form and technique
- Process video footage efficiently and produce easy-to-understand outputs
The Solution
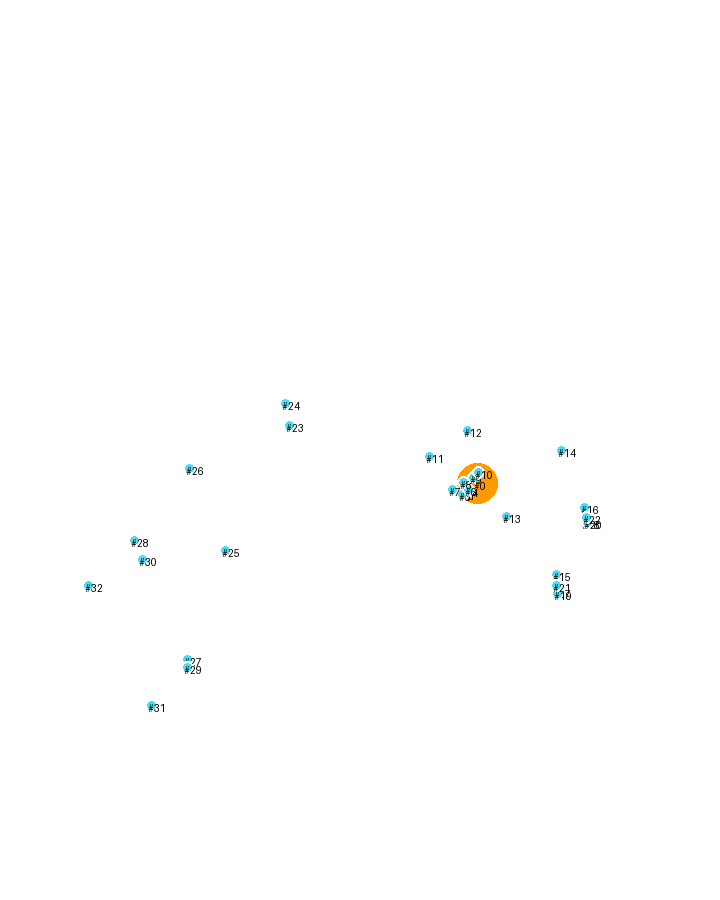
Using MediaPipe's pose estimation model, we developed a Python-based tool that addresses these needs by automatically extracting clear pose diagrams from video footage. The system automatically identifies 33 key body landmarks and creates visual representations that are much simpler and easier to understand than raw video footage.
Technical Implementation
The core of the solution uses MediaPipe's pose landmark model, which can accurately detect 33 different body landmarks - from facial features to toe positions. Our implementation:
- Uses OpenCV for video frame extraction
- Employs PIL for image manipulation and overlay creation
- Generates three types of output for each processed frame:
- The original frame
- A pose overlay with connected landmarks
- A composite image combining both
Example Output
The tool produces three views of each analyzed frame:
- Original video frame
- Pose detection overlay with numbered landmarks
- Composite view combining both
Each landmark is clearly marked and connected, making it easy to analyze form and technique. The nose landmark (#0) is highlighted with a larger orange marker, while other points use a distinctive blue color scheme for clear visibility.
Future Steps
Two key enhancements that interest me for future development:
- Implementation of automated joint angle calculations to provide precise measurements of body positions and movements
- Integration of AI image generation capabilities to transform pose data into simplified, customizable teaching diagrams