Pandas Cheat Sheet
Importing Pandas
import pandas as pd
Loading a CSV or JSON file
df = pd.read_csv('Transactions.csv')
df = pd.read_json('Data.csv')
Dropping a column
df = df.drop(['Balance'], axis=1)
Examining Column Data Types
df.dtypes
Date object
Description object
Credit float64
Debit float64
dtype: object
Converting a Column to Datetime
df['Date'] = pd.to_datetime(df['Date'], format="%d/%m/%Y")
Combining two columns
df['Amount'] = df.bfill(axis=1).iloc[:, 2]
Check for Nulls
df.isnan().values.any()
Set More useful table display widths
pd.set_option('display.max_rows', 500)
pd.set_option('display.max_columns', 500)
pd.set_option('display.width', 1000)
Extract a Regex into a new column
df['Extract'] = df['Description'].str.extract('(.*) - (Visa Purchase|Osko Payment|Internal Transfer|Receipt)')
Pandas number formatting options
pd.set_option('display.float_format', lambda x: f'{x:.3f}')
pd.set_option('display.float_format', lambda x: f'{x:,.3f}')
pd.set_option('display.precision', 2) # set max decimal places in dataframe
Load CSV
df=pd.read_csv('allcars.csv', index_col=0, low_memory=False)
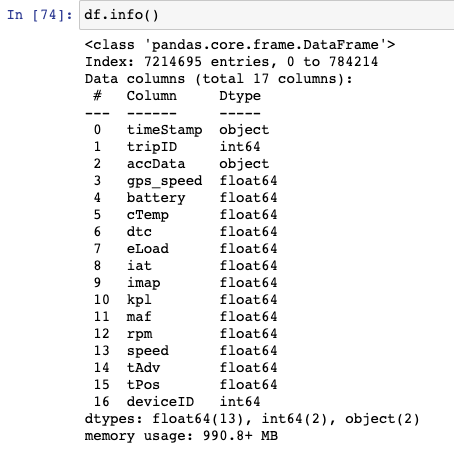
DataFrames Info
df.info()
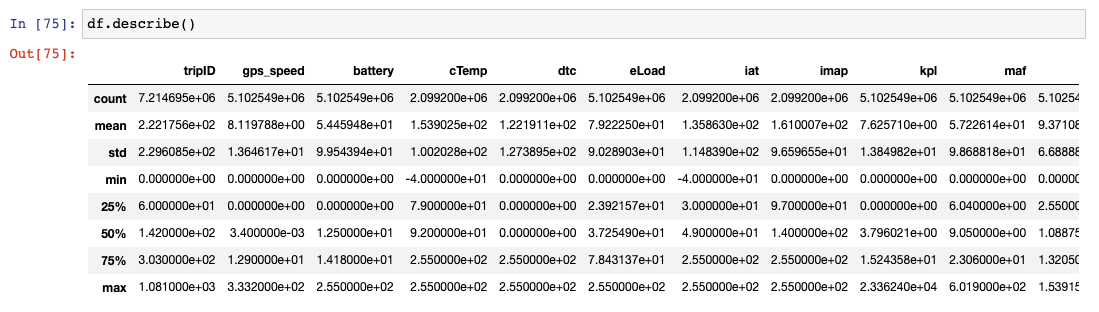
DataFrames Description
df.describe()
df['SalePrice'].describe()
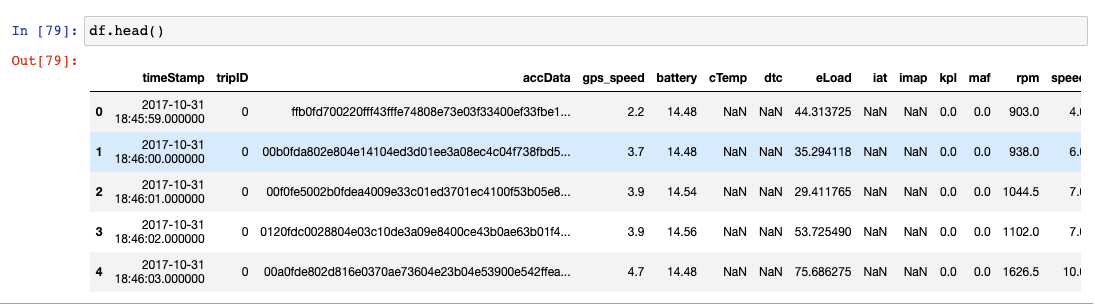
DataFrames Head
df.head()
Merging DataFrames
pd.concat([dataframe1, dataframe2], ignore_index = True) # vertically
pd.concat([dataframe1, dataframe2], axis=1) # horizontally
## merge two dataframes based on nearest time with a 60s window
merge.merge_asof(df1, df2, on=’time’, by=’ticker’, tolerance=pd.Timedelta(‘60s’)), direction = ‘nearest’
DataFrames misc...
df.shape
df.columns
df.isna()
df.isnull()
Convert Column Types
df['timeStamp'] = pd.to_datetime(df['timeStamp'])
Sort by Columns
df.sort_values(['speed','tPos'], ascending=[False, True]).head()
Column Operations
df['deviceID'].value_counts()
df[['tripID','deviceID']].value_counts()
Unique Values
df['deviceID'].unique()
Create a Subset of Columns
df_subset=df[[‘tripID’,’deviceID’,’speed’]]
df_subset.head()
Set the Index Column
df.set_index('Name')
df.reset_index()
Filter Rows / Columns
df[df['tripID']==0]
By Label
df.loc[(df.tripID == 0) & (df.deviceID == 1) & (df.speed > 10)]
By Index
df.iloc[0:4, 0:3] # row slicing, column slicing
Aggregates
df.groupby('deviceID')['speed'].mean()
df.groupby('deviceID')['speed'].max()
df['speed'].max()
df['speed'].min()
df['speed'].sum()
Visualisations
ref: https://www.kaggle.com/code/pmarcelino/comprehensive-data-exploration-with-python/notebook
Histograms and Distributions
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
sns.displot(df['speed'])
sns.histplot(df['speed'])
sns.histplot(df.loc[(df['gps_speed'] > 0)]['gps_speed'])
## set axis limts
ax = sns.histplot(df['gps_speed'])
ax.set(ylim=(0,100000))
ax.set(xlim=(0,100))
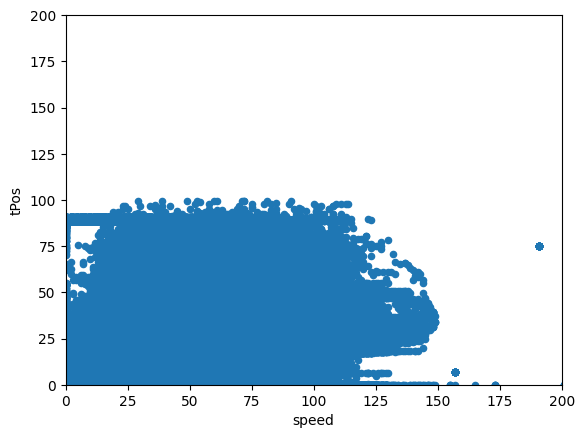
Scatter Plots
data=pd.concat([df['tPos'], df['speed']], axis=1)
data.plot.scatter(x='speed',y='tPos', ylim=(0, 200), xlim=(0,200))
Correlation Matrix
# overall data frame
corrmat = df.corr()
f, ax = plt.subplots(figsize=(12, 9))
sns.heatmap(corrmat, vmax=.8, square=True);
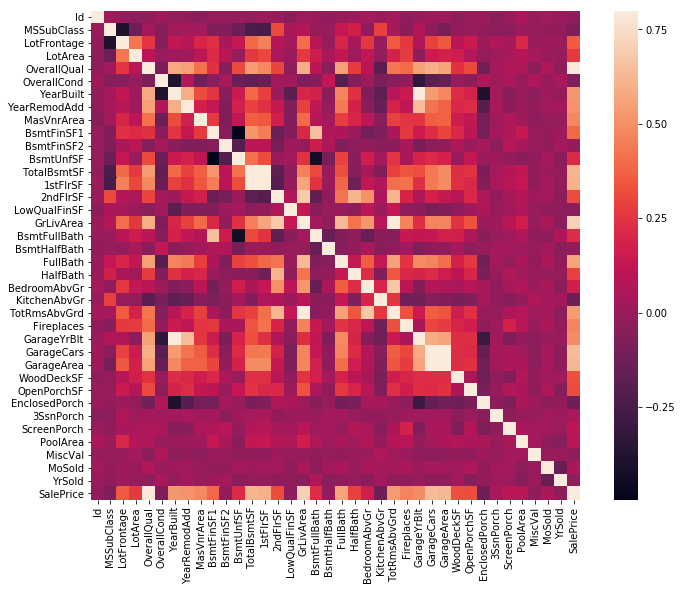
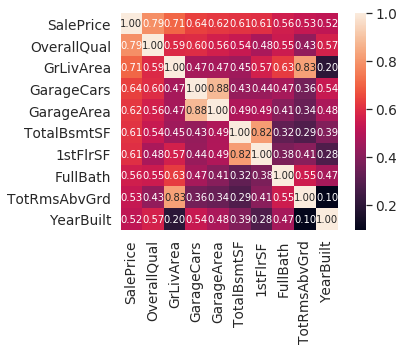
# saleprice correlation matrix
k = 10 # number of variables for heatmap
cols = corrmat.nlargest(k, 'SalePrice')['SalePrice'].index
cm = np.corrcoef(df_train[cols].values.T)
sns.set(font_scale=1.25)
hm = sns.heatmap(cm, cbar=True, annot=True, square=True, fmt='.2f', annot_kws={'size': 10}, yticklabels=cols.values, xticklabels=cols.values)
plt.show()
Variable Pair Correlations
train_df=df[['rpm', 'kpl', 'gps_speed']].dropna()
sns.set()
sns.pairplot(train_df, height=2.5)
plt.show()

Load JSON data
file_name="TMA_20230727_TTD_Sample/202307270000020e05-001_TTD_DAT_251690415988069.json"
import json
with open(file_name) as data_file:
file_contents = data_file.read()
parsed_json = json.loads(file_contents)
Load JSON into Pandas DataFrame
df = pd.json_normalize(parsed_json,
record_path =['deviceRecords', 'records'],
meta=['tdeVersion', 'batchId', ['deviceRecords','device','id']]
)